Analysis, visualization, and integration of spatial datasets with Seurat
Compiled: 2023-03-23
Source:vignettes/spatial_vignette.Rmd
spatial_vignette.RmdOverview
This tutorial demonstrates how to use Seurat (>=3.2) to analyze spatially-resolved RNA-seq data. While the analytical pipelines are similar to the Seurat workflow for single-cell RNA-seq analysis, we introduce updated interaction and visualization tools, with a particular emphasis on the integration of spatial and molecular information. This tutorial will cover the following tasks, which we believe will be common for many spatial analyses:
- Normalization
- Dimensional reduction and clustering
- Detecting spatially-variable features
- Interactive visualization
- Integration with single-cell RNA-seq data
- Working with multiple slices
For our first vignette, we analyze a dataset generated with the Visium technology from 10x Genomics. We will be extending Seurat to work with additional data types in the near-future, including SLIDE-Seq, STARmap, and MERFISH.
First, we load Seurat and the other packages necessary for this vignette.
10x Visium
Dataset
Here, we will be using a recently released dataset of sagital mouse brain slices generated using the Visium v1 chemistry. There are two serial anterior sections, and two (matched) serial posterior sections.
You can download the data here, and load it into Seurat using the Load10X_Spatial() function. This reads in the output of the spaceranger pipeline, and returns a Seurat object that contains both the spot-level expression data along with the associated image of the tissue slice. You can also use our SeuratData package for easy data access, as demonstrated below. After installing the dataset, you can type ?stxBrain to learn more.
InstallData("stxBrain")
brain <- LoadData("stxBrain", type = "anterior1")How is the spatial data stored within Seurat?
The visium data from 10x consists of the following data types:
- A spot by gene expression matrix
- An image of the tissue slice (obtained from H&E staining during data acquisition)
- Scaling factors that relate the original high resolution image to the lower resolution image used here for visualization.
Assay but contains spot level, not single-cell level data. The image itself is stored in a new images slot in the Seurat object. The images slot also stores the information necessary to associate spots with their physical position on the tissue image.
Data preprocessing
The initial preprocessing steps that we perform on the spot by gene expression data are similar to a typical scRNA-seq experiment. We first need to normalize the data in order to account for variance in sequencing depth across data points. We note that the variance in molecular counts / spot can be substantial for spatial datasets, particularly if there are differences in cell density across the tissue. We see substantial heterogeneity here, which requires effective normalization.
plot1 <- VlnPlot(brain, features = "nCount_Spatial", pt.size = 0.1) + NoLegend()
plot2 <- SpatialFeaturePlot(brain, features = "nCount_Spatial") + theme(legend.position = "right")
wrap_plots(plot1, plot2)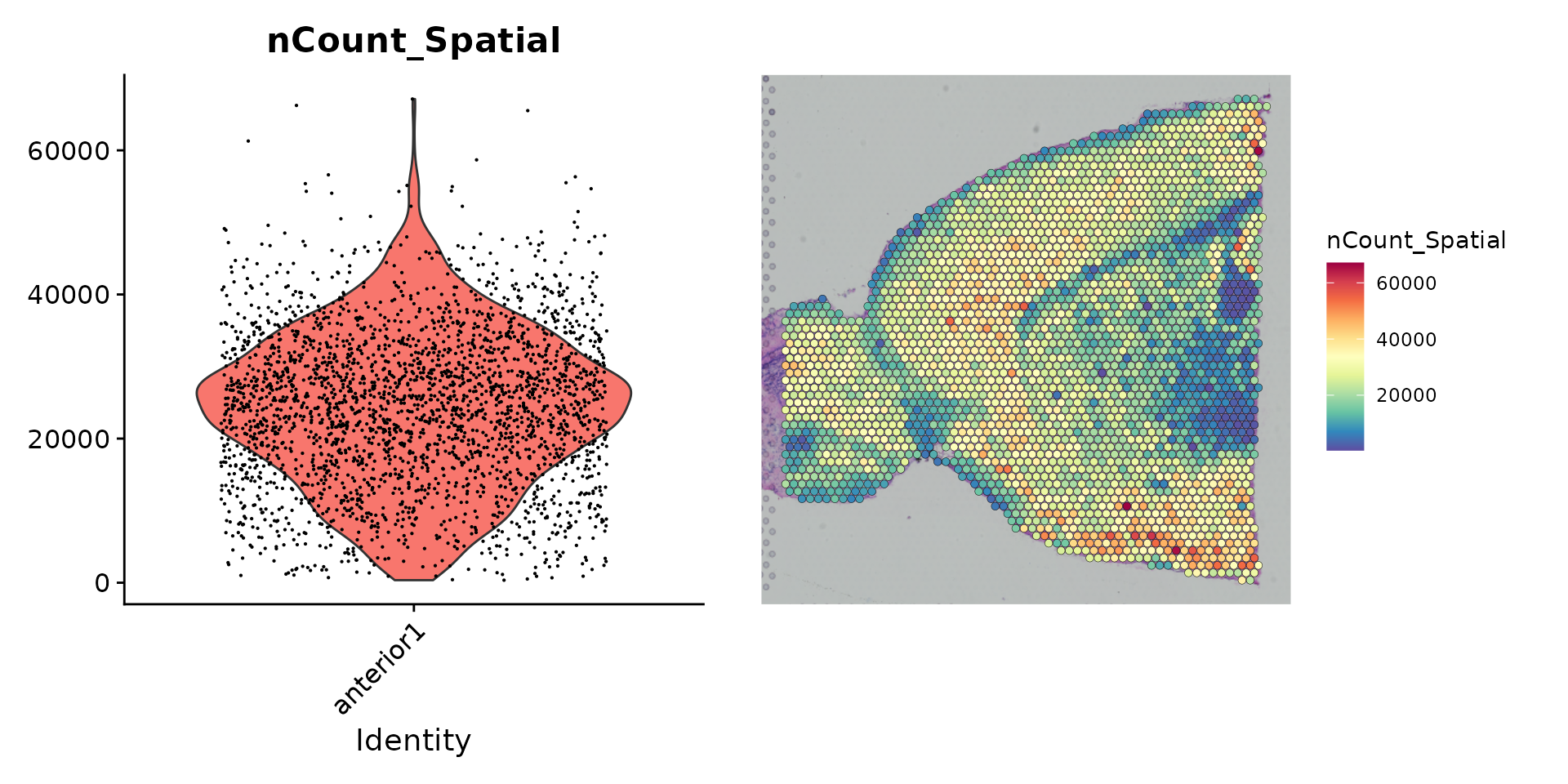
These plots demonstrate that the variance in molecular counts across spots is not just technical in nature, but also is dependent on the tissue anatomy. For example, regions of the tissue that are depleted for neurons (such as the cortical white matter), reproducibly exhibit lower molecular counts. As a result, standard approaches (such as the LogNormalize() function), which force each data point to have the same underlying ‘size’ after normalization, can be problematic.
As an alternative, we recommend using sctransform (Hafemeister and Satija, Genome Biology 2019), which which builds regularized negative binomial models of gene expression in order to account for technical artifacts while preserving biological variance. For more details on sctransform, please see the paper here and the Seurat vignette here. sctransform normalizes the data, detects high-variance features, and stores the data in the SCT assay.
brain <- SCTransform(brain, assay = "Spatial", verbose = FALSE)How do results compare to log-normalization?
To explore the differences in normalization methods, we examine how both the sctransform and log normalization results correlate with the number of UMIs. For this comparison, we first rerun sctransform to store values for all genes and run a log-normalization procedure via NormalizeData().
# rerun normalization to store sctransform residuals for all genes
brain <- SCTransform(brain, assay = "Spatial", return.only.var.genes = FALSE, verbose = FALSE)
# also run standard log normalization for comparison
brain <- NormalizeData(brain, verbose = FALSE, assay = "Spatial")
# Computes the correlation of the log normalized data and sctransform residuals with the
# number of UMIs
brain <- GroupCorrelation(brain, group.assay = "Spatial", assay = "Spatial", slot = "data", do.plot = FALSE)
brain <- GroupCorrelation(brain, group.assay = "Spatial", assay = "SCT", slot = "scale.data", do.plot = FALSE)
p1 <- GroupCorrelationPlot(brain, assay = "Spatial", cor = "nCount_Spatial_cor") + ggtitle("Log Normalization") +
theme(plot.title = element_text(hjust = 0.5))
p2 <- GroupCorrelationPlot(brain, assay = "SCT", cor = "nCount_Spatial_cor") + ggtitle("SCTransform Normalization") +
theme(plot.title = element_text(hjust = 0.5))
p1 + p2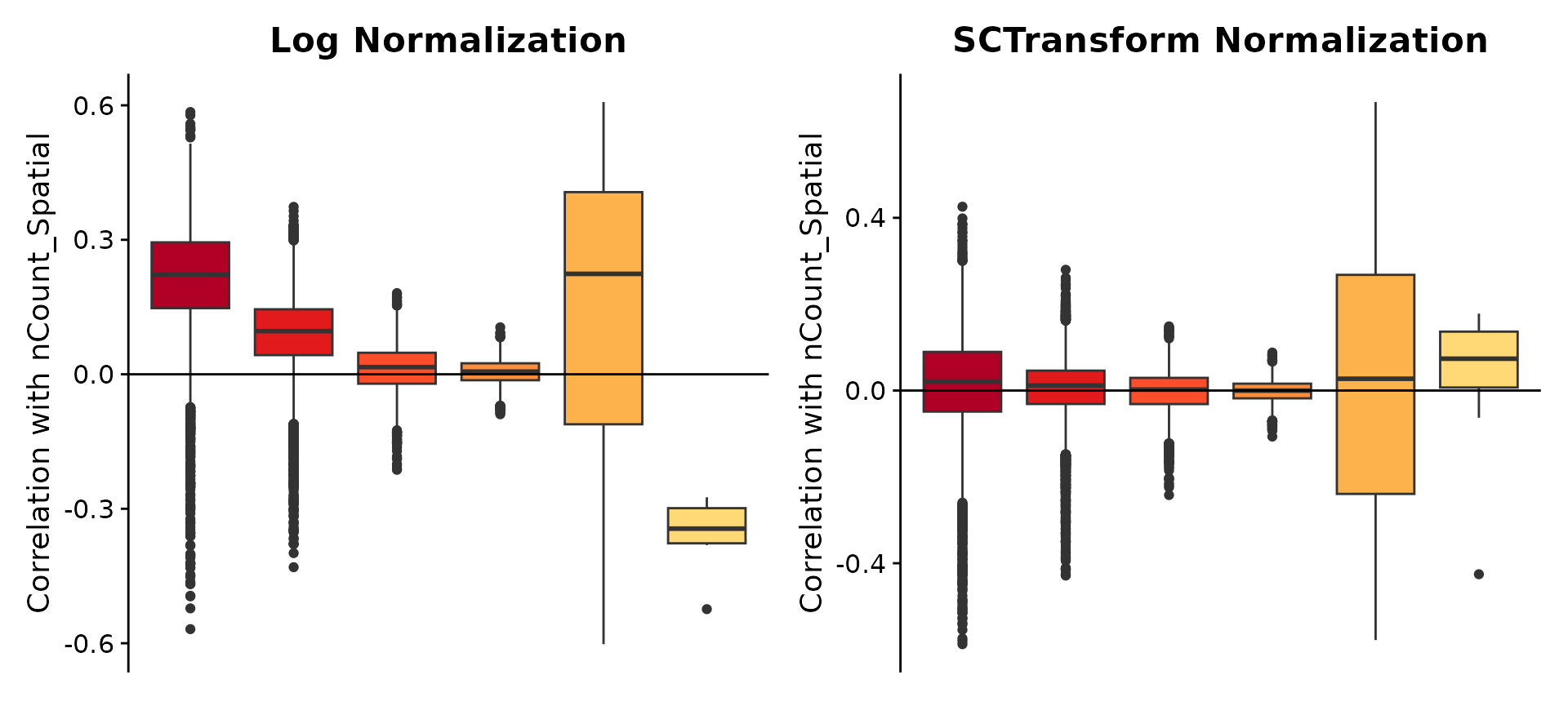
nCount_Spatial variable here). We then place genes into groups based on their mean expression, and generate boxplots of these correlations. You can see that log-normalization fails to adequately normalize genes in the first three groups, suggesting that technical factors continue to influence normalized expression estimates for highly expressed genes. In contrast, sctransform normalization substantially mitigates this effect.
Gene expression visualization
In Seurat, we have functionality to explore and interact with the inherently visual nature of spatial data. The SpatialFeaturePlot() function in Seurat extends FeaturePlot(), and can overlay molecular data on top of tissue histology. For example, in this data set of the mouse brain, the gene Hpca is a strong hippocampus marker and Ttr is a marker of the choroid plexus.
SpatialFeaturePlot(brain, features = c("Hpca", "Ttr"))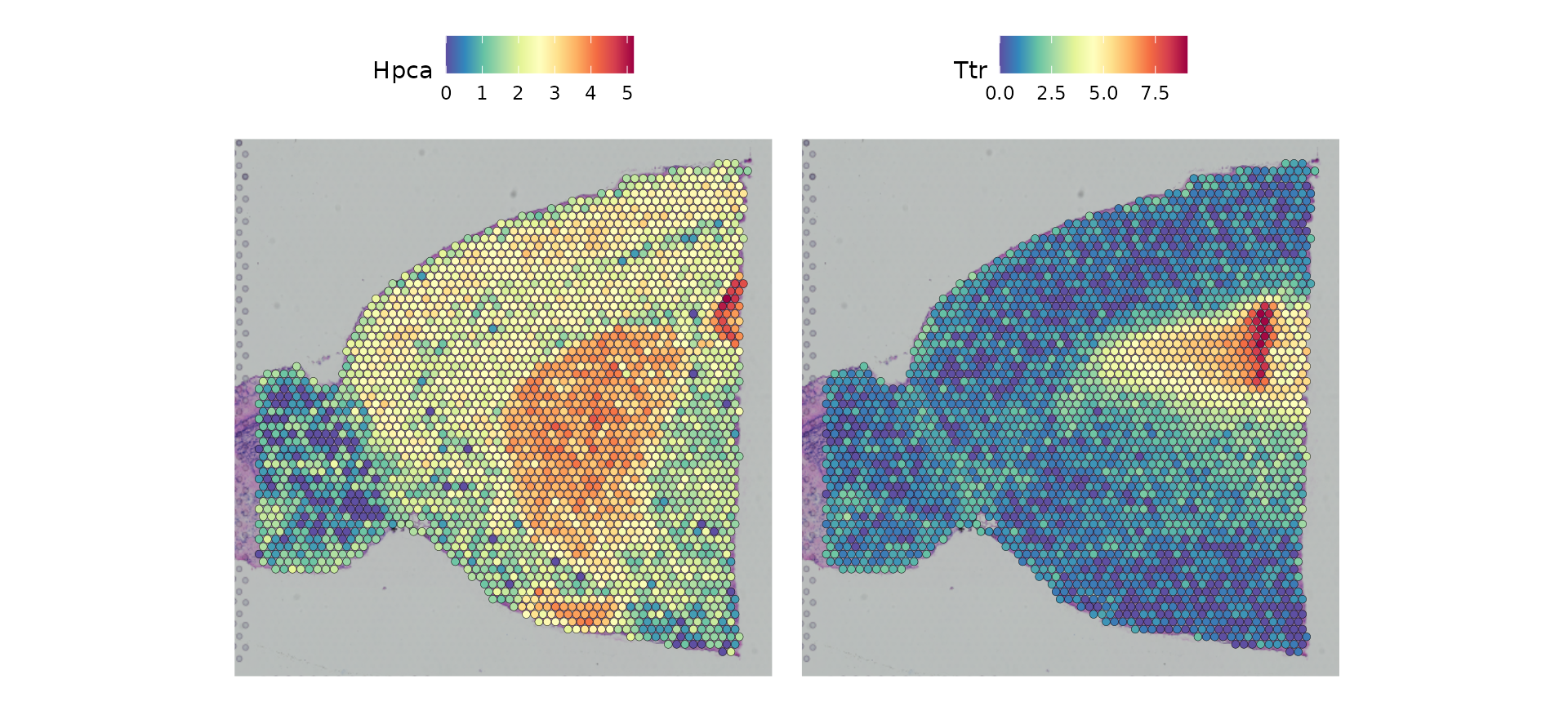
library(ggplot2)
plot <- SpatialFeaturePlot(brain, features = c("Ttr")) + theme(legend.text = element_text(size = 0),
legend.title = element_text(size = 20), legend.key.size = unit(1, "cm"))
jpeg(filename = "../output/images/spatial_vignette_ttr.jpg", height = 700, width = 1200, quality = 50)
print(plot)
dev.off()## agg_png
## 2The default parameters in Seurat emphasize the visualization of molecular data. However, you can also adjust the size of the spots (and their transparency) to improve the visualization of the histology image, by changing the following parameters:
-
pt.size.factor- This will scale the size of the spots. Default is 1.6 -
alpha- minimum and maximum transparency. Default is c(1, 1). - Try setting to
alphac(0.1, 1), to downweight the transparency of points with lower expression
p1 <- SpatialFeaturePlot(brain, features = "Ttr", pt.size.factor = 1)
p2 <- SpatialFeaturePlot(brain, features = "Ttr", alpha = c(0.1, 1))
p1 + p2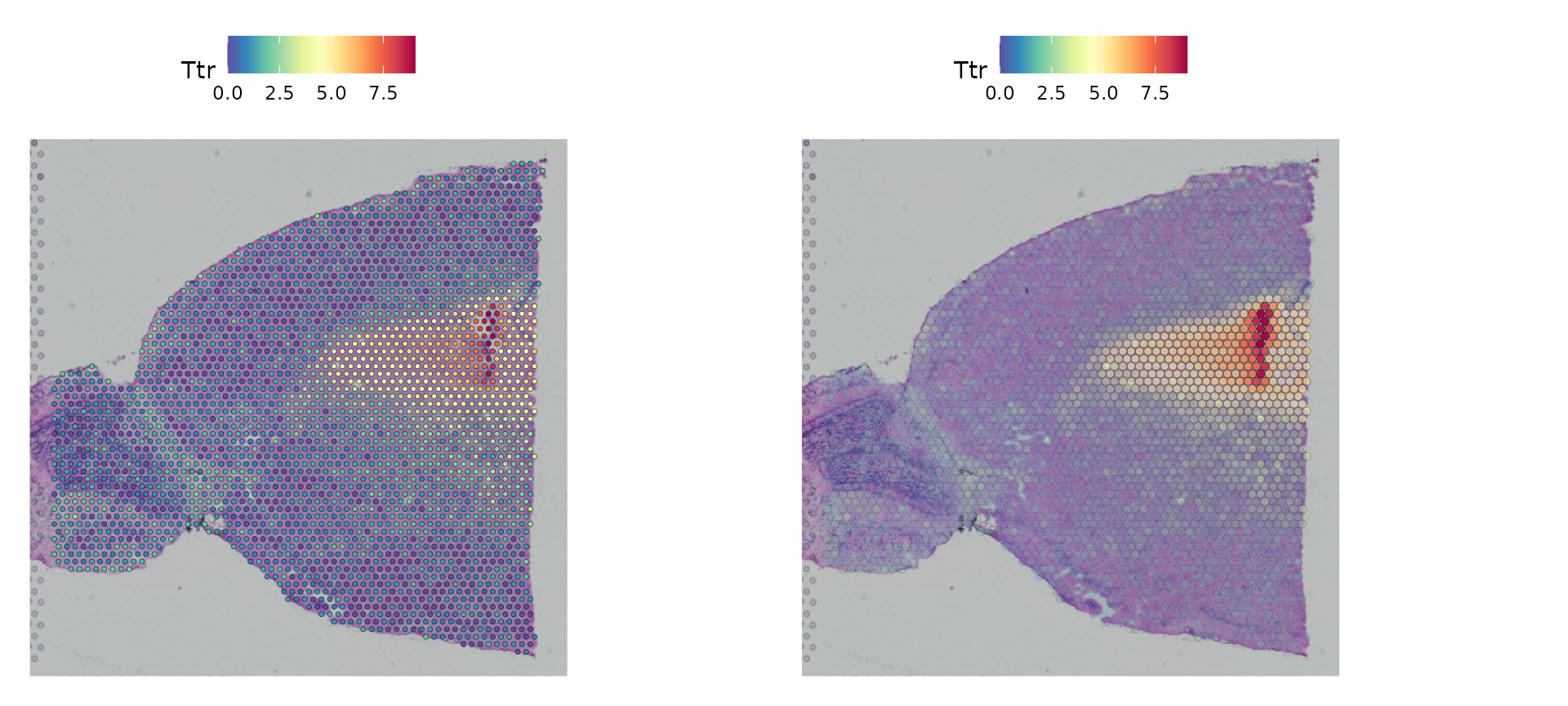
Dimensionality reduction, clustering, and visualization
We can then proceed to run dimensionality reduction and clustering on the RNA expression data, using the same workflow as we use for scRNA-seq analysis.
brain <- RunPCA(brain, assay = "SCT", verbose = FALSE)
brain <- FindNeighbors(brain, reduction = "pca", dims = 1:30)
brain <- FindClusters(brain, verbose = FALSE)
brain <- RunUMAP(brain, reduction = "pca", dims = 1:30)We can then visualize the results of the clustering either in UMAP space (with DimPlot()) or overlaid on the image with SpatialDimPlot().
p1 <- DimPlot(brain, reduction = "umap", label = TRUE)
p2 <- SpatialDimPlot(brain, label = TRUE, label.size = 3)
p1 + p2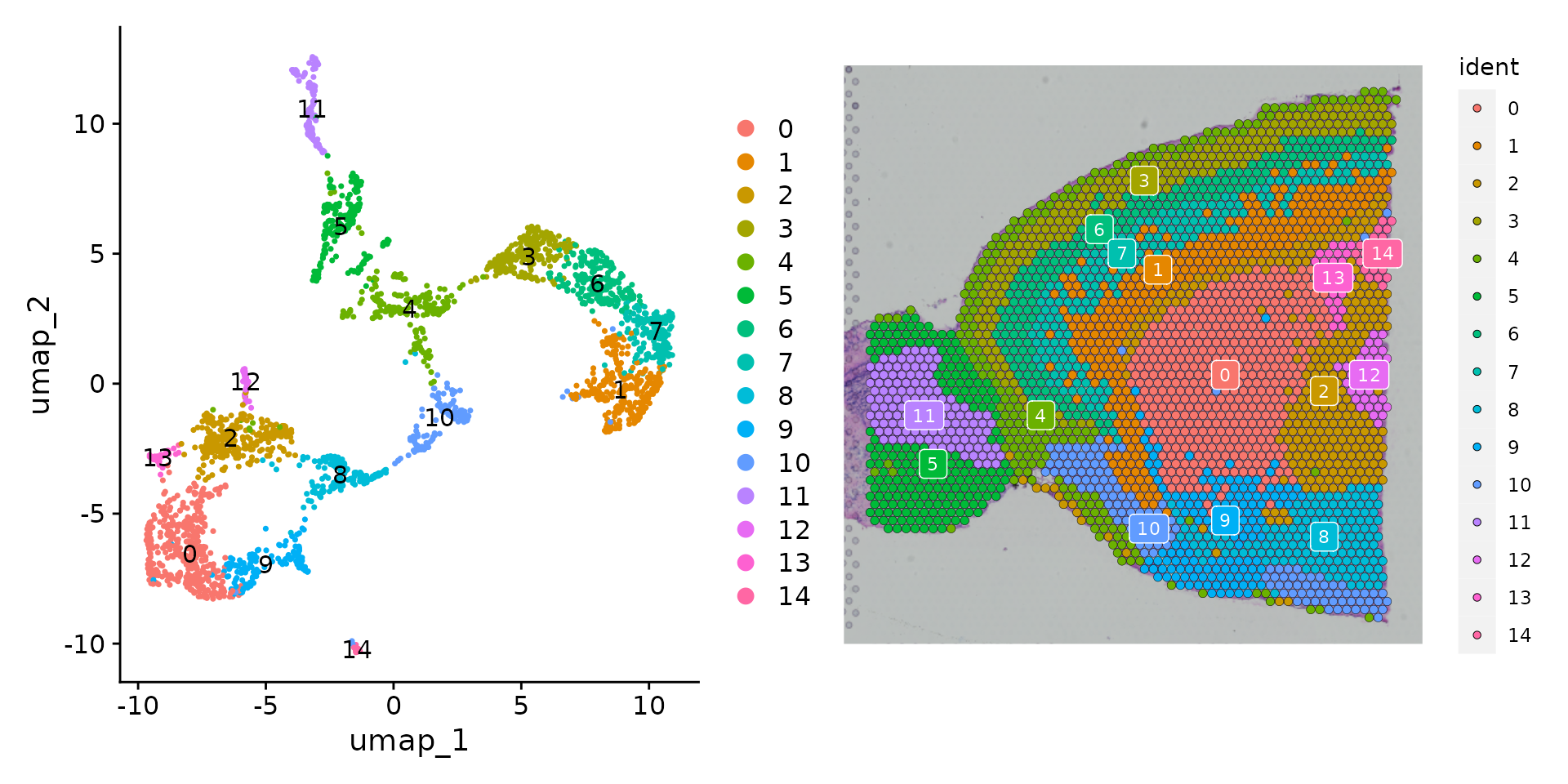 As there are many colors, it can be challenging to visualize which voxel belongs to which cluster. We have a few strategies to help with this. Setting the
As there are many colors, it can be challenging to visualize which voxel belongs to which cluster. We have a few strategies to help with this. Setting the label parameter places a colored box at the median of each cluster (see the plot above).
You can also use the cells.highlight parameter to demarcate particular cells of interest on a SpatialDimPlot(). This can be very useful for distinguishing the spatial localization of individual clusters, as we show below:
SpatialDimPlot(brain, cells.highlight = CellsByIdentities(object = brain, idents = c(2, 1, 4, 3,
5, 8)), facet.highlight = TRUE, ncol = 3)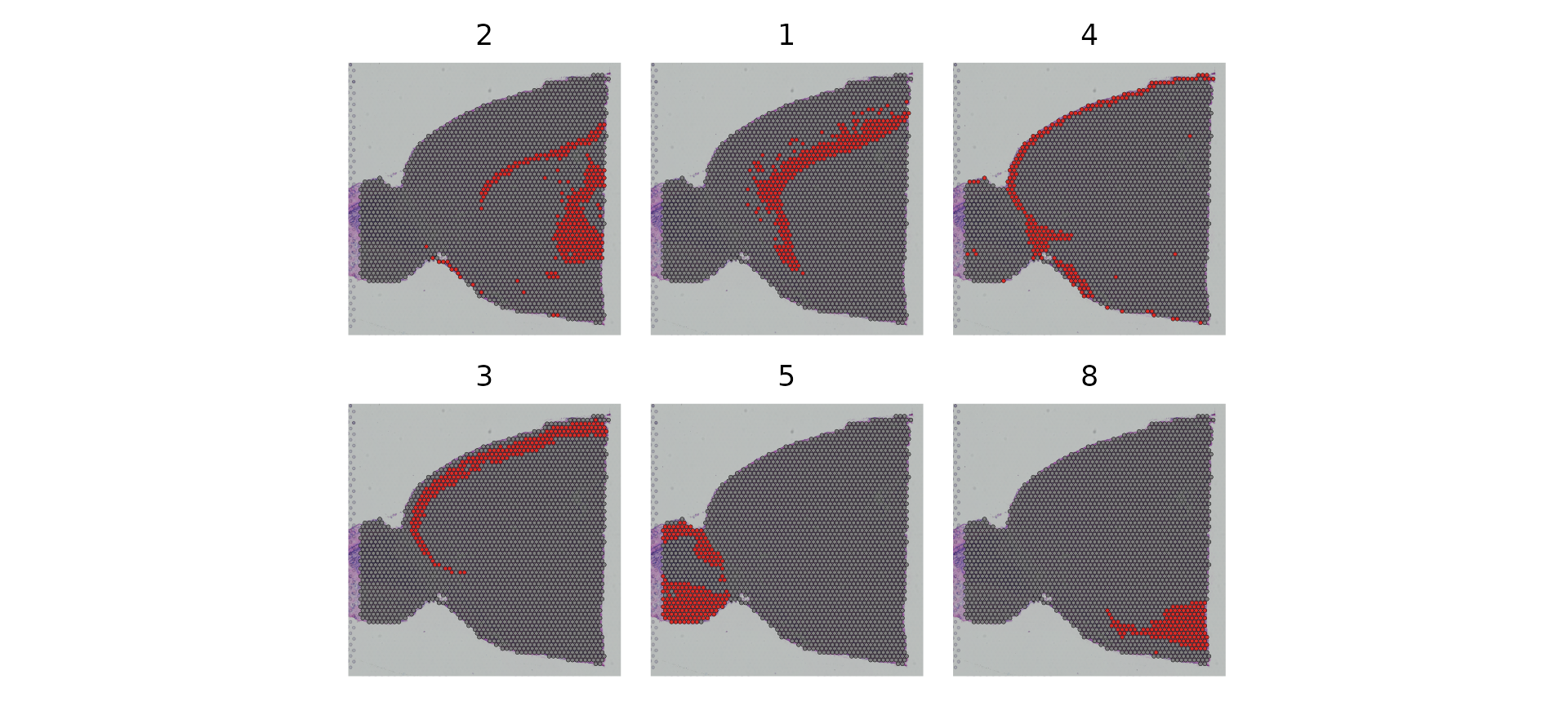
Interactive plotting
We have also built in a number of interactive plotting capabilities. Both SpatialDimPlot() and SpatialFeaturePlot() now have an interactive parameter, that when set to TRUE, will open up the Rstudio viewer pane with an interactive Shiny plot. The example below demonstrates an interactive SpatialDimPlot() in which you can hover over spots and view the cell name and current identity class (analogous to the previous do.hover behavior).
SpatialDimPlot(brain, interactive = TRUE)For SpatialFeaturePlot(), setting interactive to TRUE brings up an interactive pane in which you can adjust the transparency of the spots, the point size, as well as the Assay and feature being plotted. After exploring the data, selecting the done button will return the last active plot as a ggplot object.
SpatialFeaturePlot(brain, features = "Ttr", interactive = TRUE)The LinkedDimPlot() function links the UMAP representation to the tissue image representation and allows for interactive selection. For example, you can select a region in the UMAP plot and the corresponding spots in the image representation will be highlighted.
LinkedDimPlot(brain)Identification of Spatially Variable Features
Seurat offers two workflows to identify molecular features that correlate with spatial location within a tissue. The first is to perform differential expression based on pre-annotated anatomical regions within the tissue, which may be determined either from unsupervised clustering or prior knowledge. This strategy works will in this case, as the clusters above exhibit clear spatial restriction.
de_markers <- FindMarkers(brain, ident.1 = 5, ident.2 = 6)
SpatialFeaturePlot(object = brain, features = rownames(de_markers)[1:3], alpha = c(0.1, 1), ncol = 3)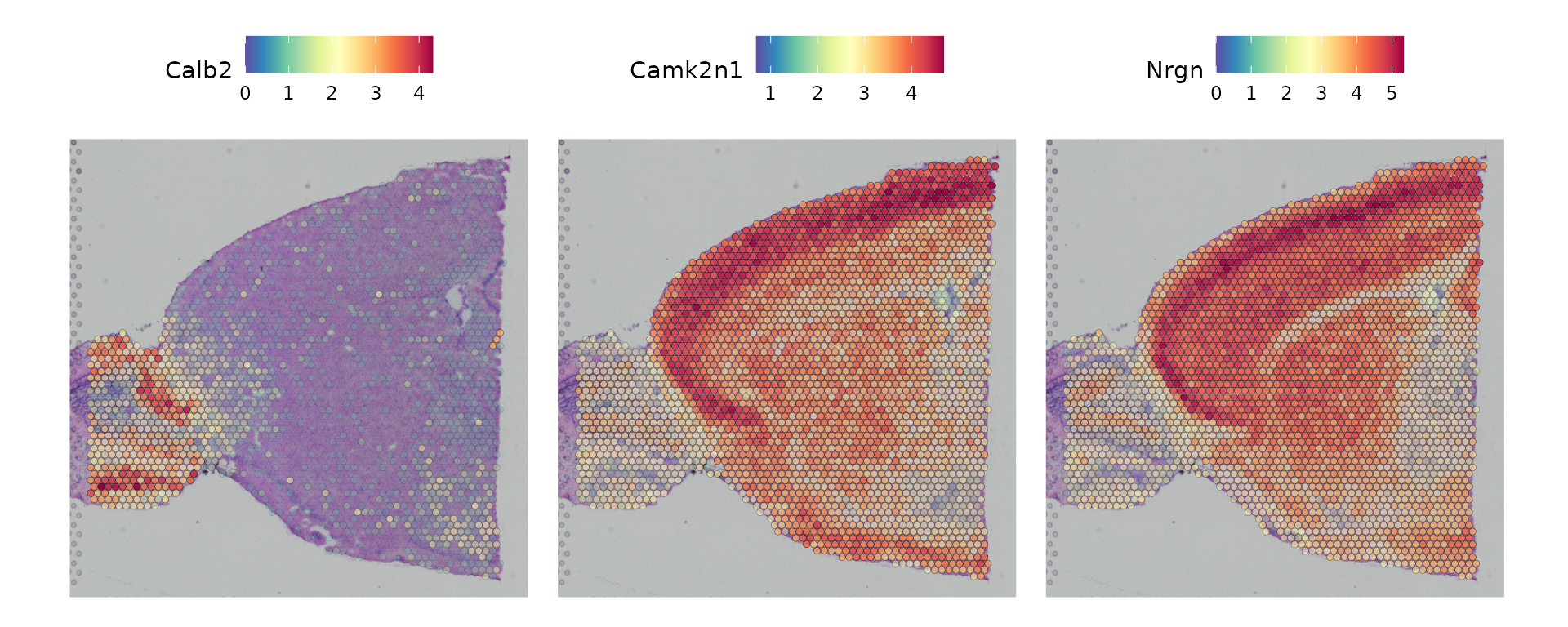
An alternative approach, implemented in FindSpatiallyVariables(), is to search for features exhibiting spatial patterning in the absence of pre-annotation. The default method (method = 'markvariogram), is inspired by the Trendsceek, which models spatial transcriptomics data as a mark point process and computes a ‘variogram’, which identifies genes whose expression level is dependent on their spatial location. More specifically, this process calculates gamma(r) values measuring the dependence between two spots a certain “r” distance apart. By default, we use an r-value of ‘5’ in these analyses, and only compute these values for variable genes (where variation is calculated independently of spatial location) to save time.
We note that there are multiple methods in the literature to accomplish this task, including SpatialDE, and Splotch. We encourage interested users to explore these methods, and hope to add support for them in the near future.
brain <- FindSpatiallyVariableFeatures(brain, assay = "SCT", features = VariableFeatures(brain)[1:1000],
selection.method = "moransi")Now we visualize the expression of the top 6 features identified by this measure.
top.features <- head(SpatiallyVariableFeatures(brain, selection.method = "moransi"), 6)
SpatialFeaturePlot(brain, features = top.features, ncol = 3, alpha = c(0.1, 1))
Subset out anatomical regions
As with single-cell objects, you can subset the object to focus on a subset of data. Here, we approximately subset the frontal cortex. This process also facilitates the integration of these data with a cortical scRNA-seq dataset in the next section. First, we take a subset of clusters, and then further segment based on exact positions. After subsetting, we can visualize the cortical cells either on the full image, or a cropped image.
cortex <- subset(brain, idents = c(1, 2, 3, 4, 6, 7))
# now remove additional cells, use SpatialDimPlots to visualize what to remove
# SpatialDimPlot(cortex,cells.highlight = WhichCells(cortex, expression = image_imagerow > 400
# | image_imagecol < 150))
cortex <- subset(cortex, anterior1_imagerow > 400 | anterior1_imagecol < 150, invert = TRUE)
cortex <- subset(cortex, anterior1_imagerow > 275 & anterior1_imagecol > 370, invert = TRUE)
cortex <- subset(cortex, anterior1_imagerow > 250 & anterior1_imagecol > 440, invert = TRUE)
p1 <- SpatialDimPlot(cortex, crop = TRUE, label = TRUE)
p2 <- SpatialDimPlot(cortex, crop = FALSE, label = TRUE, pt.size.factor = 1, label.size = 3)
p1 + p2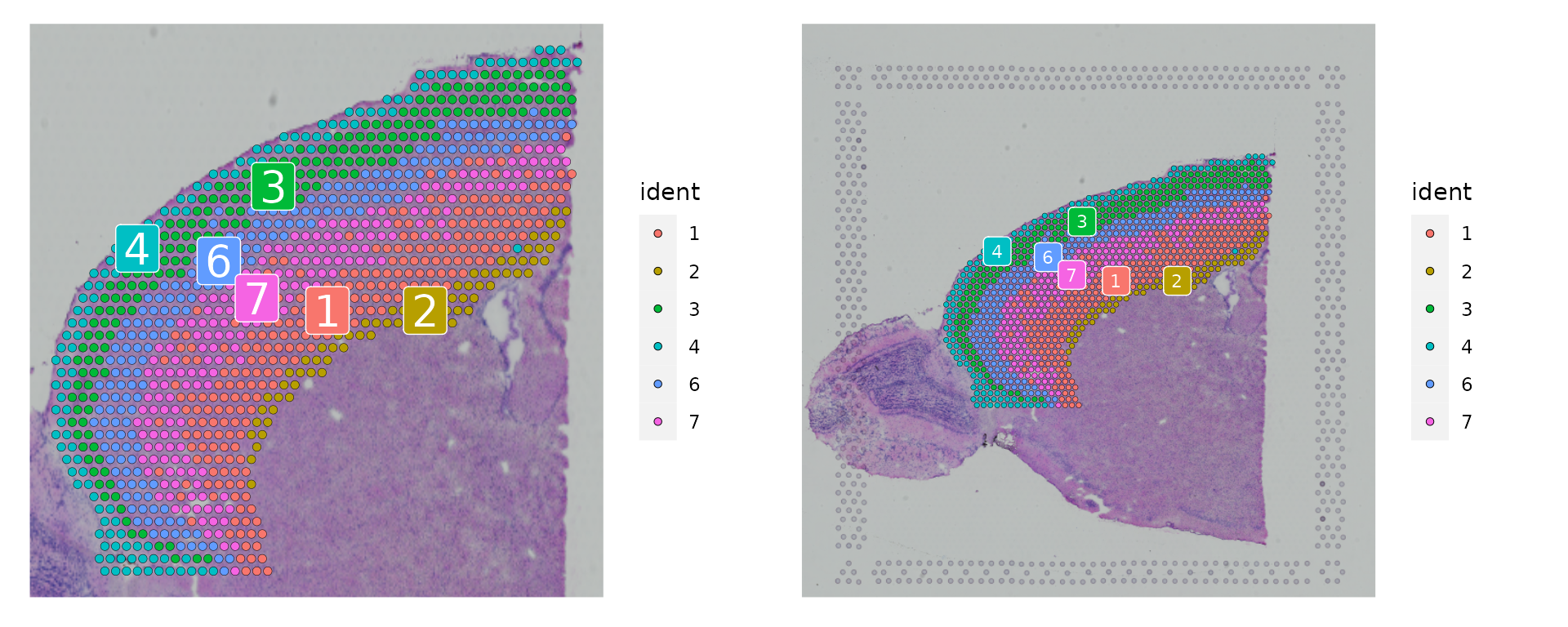
Integration with single-cell data
At ~50um, spots from the visium assay will encompass the expression profiles of multiple cells. For the growing list of systems where scRNA-seq data is available, users may be interested to ‘deconvolute’ each of the spatial voxels to predict the underlying composition of cell types. In preparing this vignette, we tested a wide variety of decovonlution and integration methods, using a reference scRNA-seq dataset of ~14,000 adult mouse cortical cell taxonomy from the Allen Institute, generated with the SMART-Seq2 protocol. We consistently found superior performance using integration methods (as opposed to deconvolution methods), likely because of substantially different noise models that characterize spatial and single-cell datasets, and integration methods are specifiically designed to be robust to these differences. We therefore apply the ‘anchor’-based integration workflow introduced in Seurat v3, that enables the probabilistic transfer of annotations from a reference to a query set. We therefore follow the label transfer workflow introduced here, taking advantage of sctransform normalization, but anticipate new methods to be developed to accomplish this task.
We first load the data (download available here), pre-process the scRNA-seq reference, and then perform label transfer. The procedure outputs, for each spot, a probabilistic classification for each of the scRNA-seq derived classes. We add these predictions as a new assay in the Seurat object.
allen_reference <- readRDS("../data/allen_cortex.rds")
# note that setting ncells=3000 normalizes the full dataset but learns noise models on 3k
# cells this speeds up SCTransform dramatically with no loss in performance
library(dplyr)
allen_reference <- SCTransform(allen_reference, ncells = 3000, verbose = FALSE) %>%
RunPCA(verbose = FALSE) %>%
RunUMAP(dims = 1:30)
# After subsetting, we renormalize cortex
cortex <- SCTransform(cortex, assay = "Spatial", verbose = FALSE) %>%
RunPCA(verbose = FALSE)
# the annotation is stored in the 'subclass' column of object metadata
DimPlot(allen_reference, group.by = "subclass", label = TRUE)
anchors <- FindTransferAnchors(reference = allen_reference, query = cortex, normalization.method = "SCT")
predictions.assay <- TransferData(anchorset = anchors, refdata = allen_reference$subclass, prediction.assay = TRUE,
weight.reduction = cortex[["pca"]], dims = 1:30)
cortex[["predictions"]] <- predictions.assayNow we get prediction scores for each spot for each class. Of particular interest in the frontal cortex region are the laminar excitatory neurons. Here we can distinguish between distinct sequential layers of these neuronal subtypes, for example:
DefaultAssay(cortex) <- "predictions"
SpatialFeaturePlot(cortex, features = c("L2/3 IT", "L4"), pt.size.factor = 1.6, ncol = 2, crop = TRUE)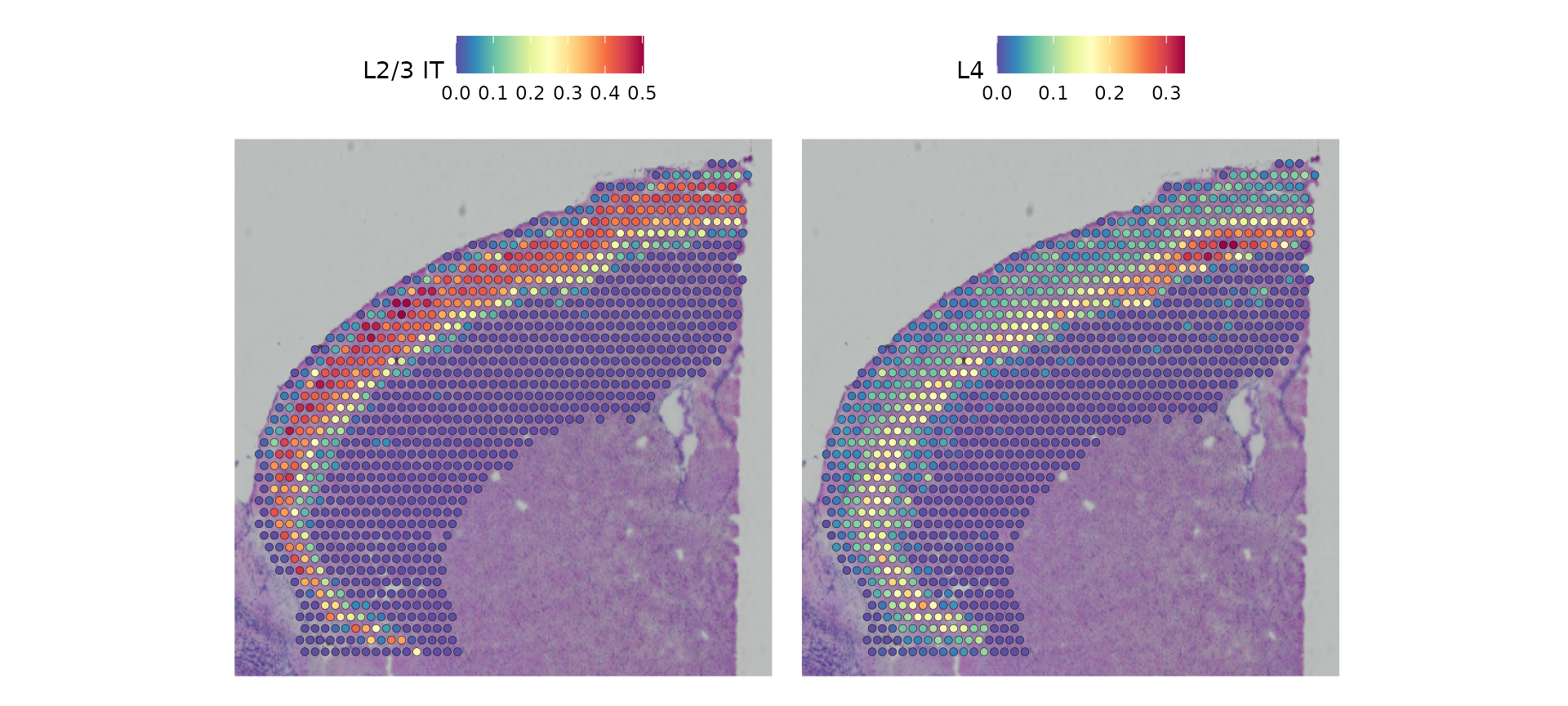
Based on these prediction scores, we can also predict cell types whose location is spatially restricted. We use the same methods based on marked point processes to define spatially variable features, but use the cell type prediction scores as the “marks” rather than gene expression.
cortex <- FindSpatiallyVariableFeatures(cortex, assay = "predictions", selection.method = "moransi",
features = rownames(cortex), r.metric = 5, slot = "data")
top.clusters <- head(SpatiallyVariableFeatures(cortex, selection.method = "moransi"), 4)
SpatialPlot(object = cortex, features = top.clusters, ncol = 2)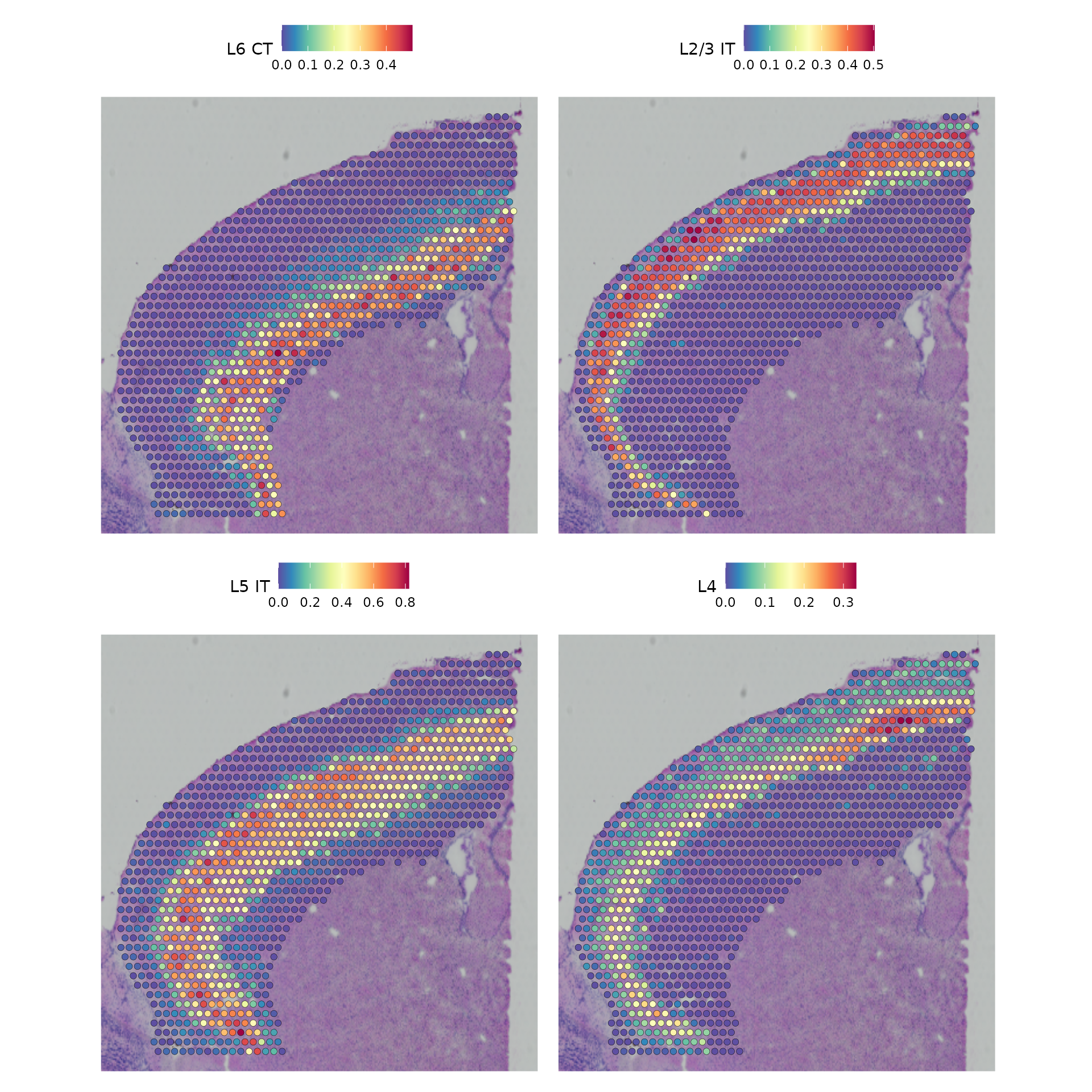
Finally, we show that our integrative procedure is capable of recovering the known spatial localization patterns of both neuronal and non-neuronal subsets, including laminar excitatory, layer-1 astrocytes, and the cortical grey matter.
SpatialFeaturePlot(cortex, features = c("Astro", "L2/3 IT", "L4", "L5 PT", "L5 IT", "L6 CT", "L6 IT",
"L6b", "Oligo"), pt.size.factor = 1, ncol = 2, crop = FALSE, alpha = c(0.1, 1))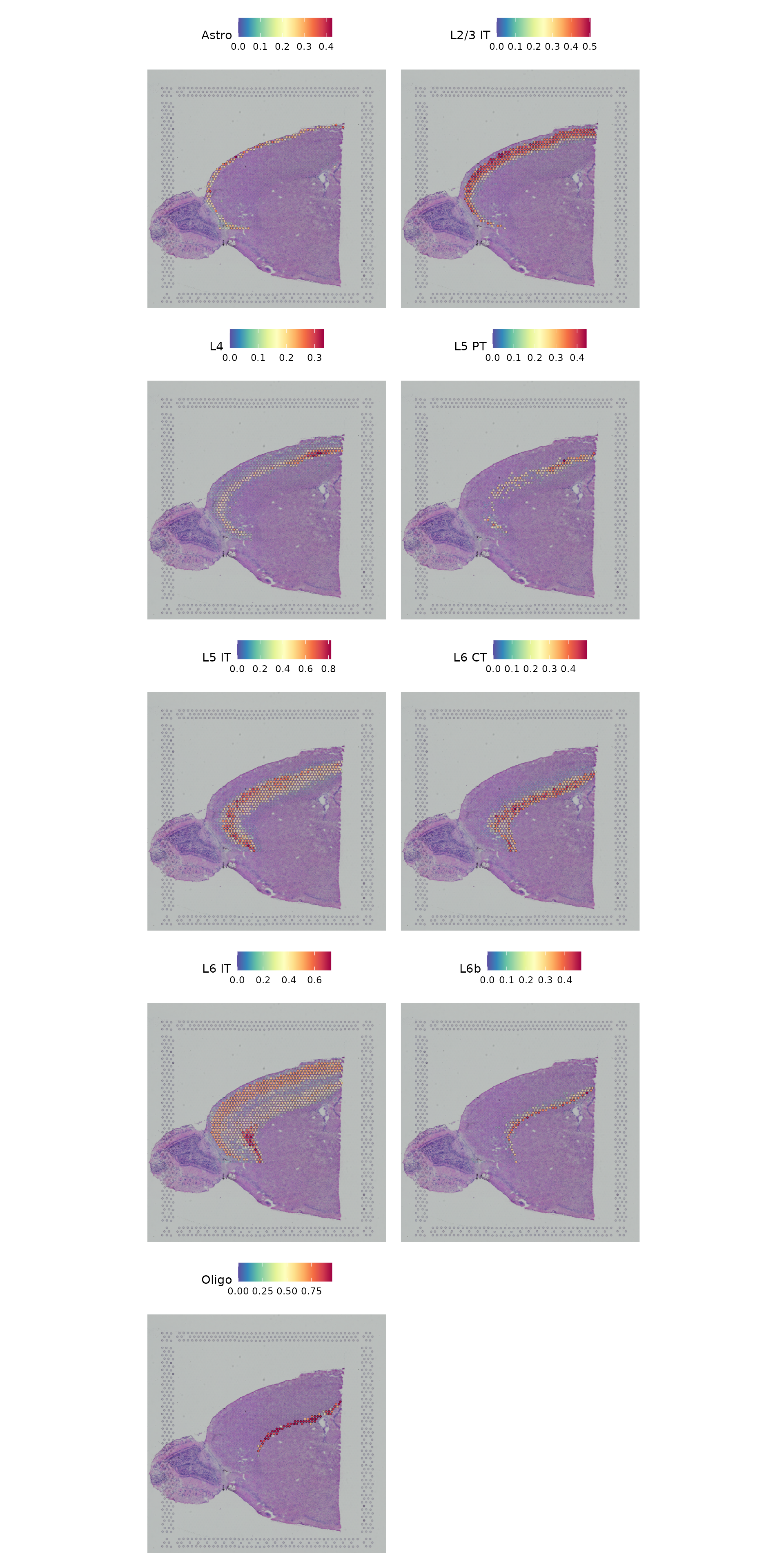
Working with multiple slices in Seurat
This dataset of the mouse brain contains another slice corresponding to the other half of the brain. Here we read it in and perform the same initial normalization.
brain2 <- LoadData("stxBrain", type = "posterior1")
brain2 <- SCTransform(brain2, assay = "Spatial", verbose = FALSE)In order to work with multiple slices in the same Seurat object, we provide the merge function.
brain.merge <- merge(brain, brain2)This then enables joint dimensional reduction and clustering on the underlying RNA expression data.
DefaultAssay(brain.merge) <- "SCT"
VariableFeatures(brain.merge) <- c(VariableFeatures(brain), VariableFeatures(brain2))
brain.merge <- RunPCA(brain.merge, verbose = FALSE)
brain.merge <- FindNeighbors(brain.merge, dims = 1:30)
brain.merge <- FindClusters(brain.merge, verbose = FALSE)
brain.merge <- RunUMAP(brain.merge, dims = 1:30)Finally, the data can be jointly visualized in a single UMAP plot. SpatialDimPlot() and SpatialFeaturePlot() will by default plot all slices as columns and groupings/features as rows.
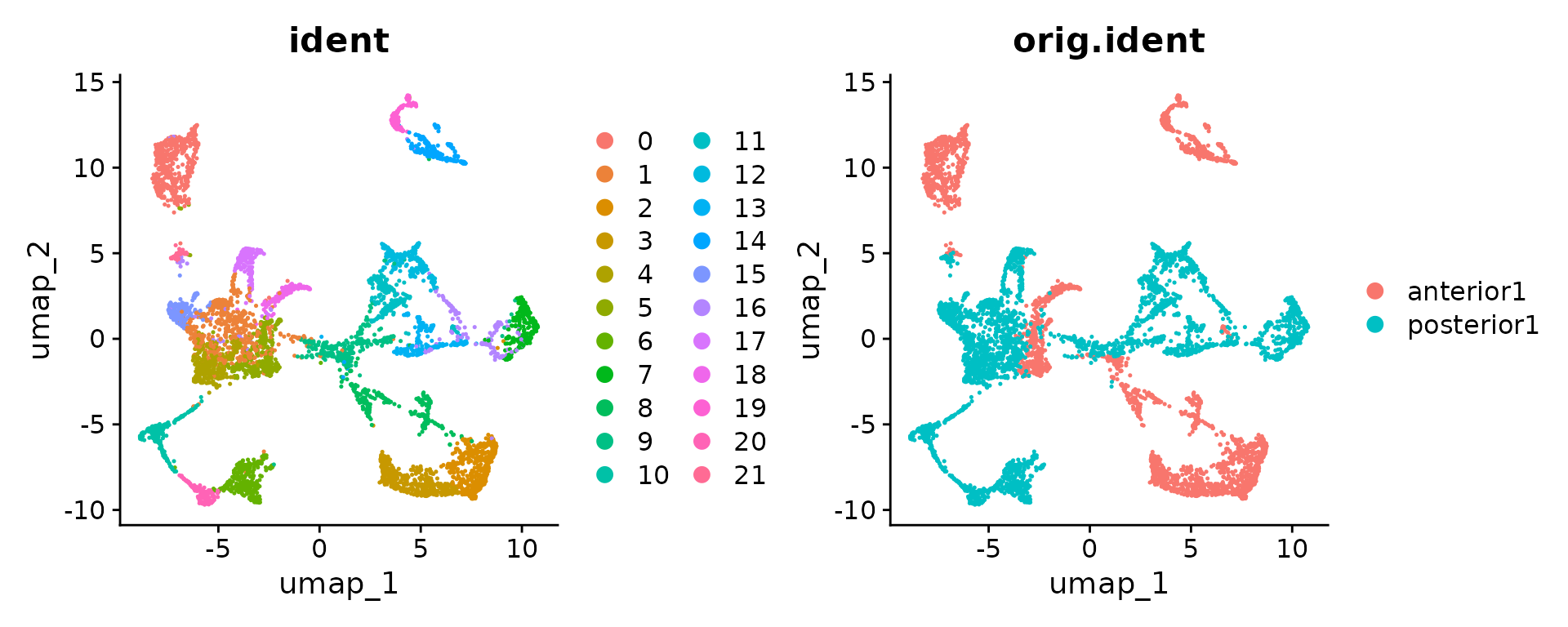
SpatialDimPlot(brain.merge)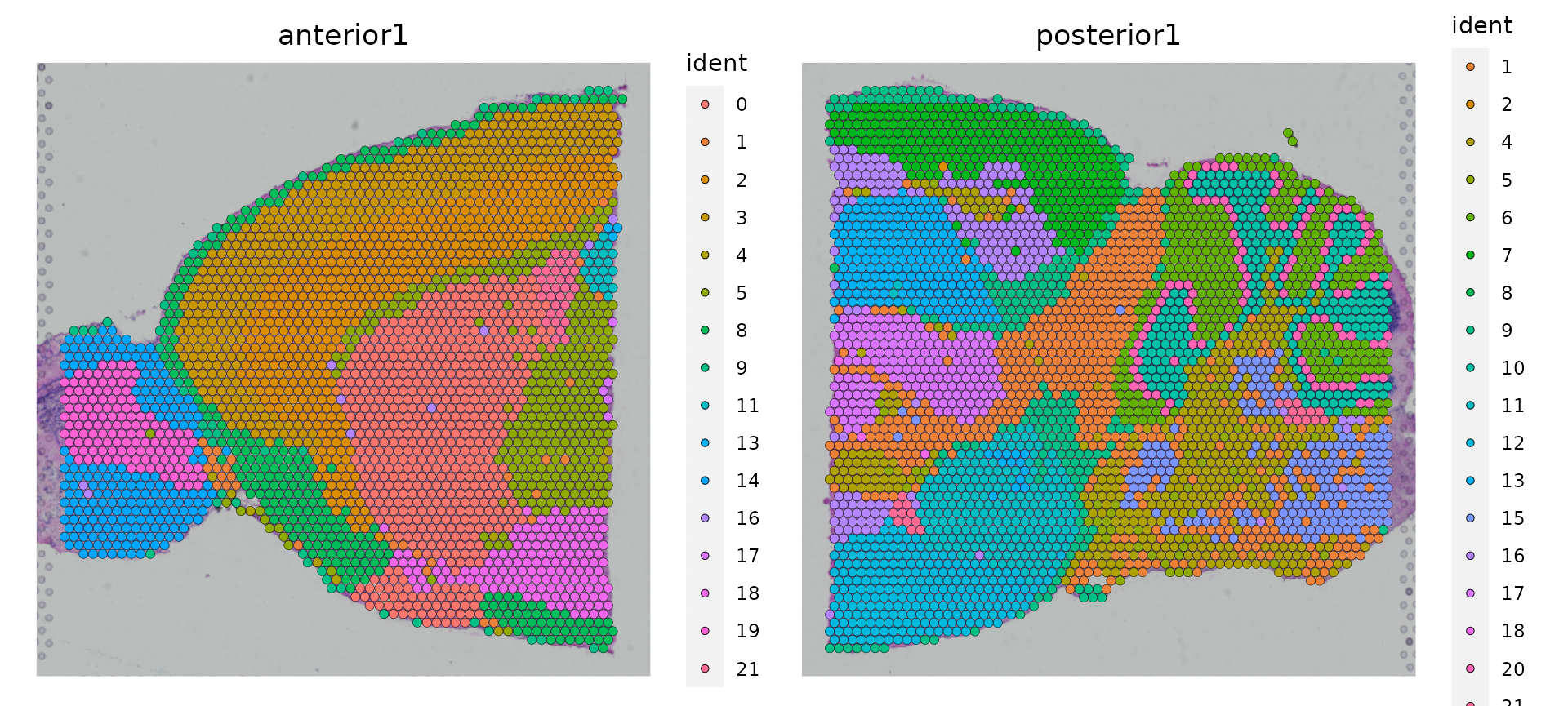
SpatialFeaturePlot(brain.merge, features = c("Hpca", "Plp1"))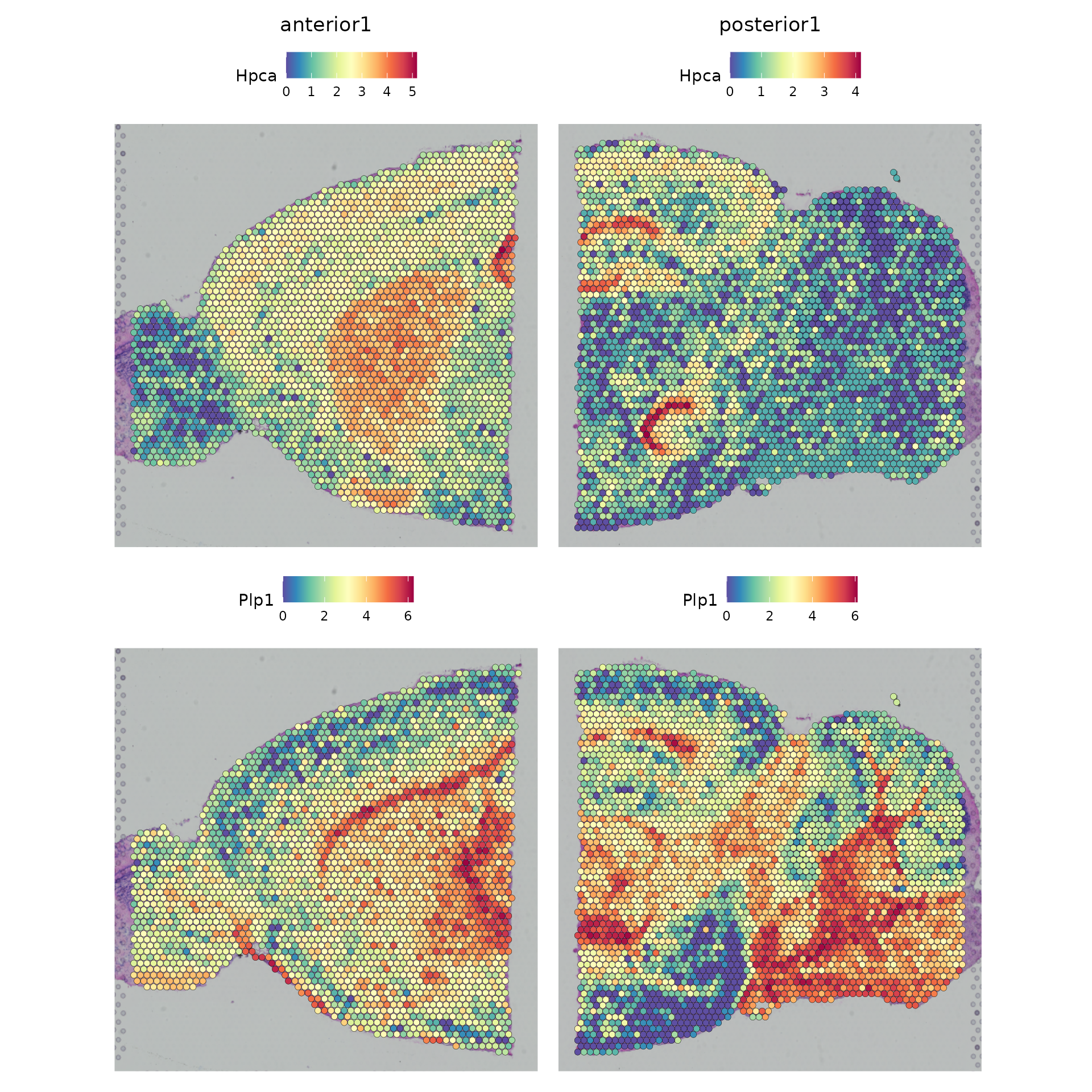
Slide-seq
Dataset
Here, we will be analyzing a dataset generated using Slide-seq v2 of the mouse hippocampus. This tutorial will follow much of the same structure as the spatial vignette for 10x Visium data but is tailored to give a demonstration specific to Slide-seq data.
You can use our SeuratData package for easy data access, as demonstrated below. After installing the dataset, you can type ?ssHippo to see the commands used to create the Seurat object.
InstallData("ssHippo")
slide.seq <- LoadData("ssHippo")Data preprocessing
The initial preprocessing steps for the bead by gene expression data are similar to other spatial Seurat analyses and to typical scRNA-seq experiments. Here, we note that many beads contain particularly low UMI counts but choose to keep all detected beads for downstream analysis.
plot1 <- VlnPlot(slide.seq, features = "nCount_Spatial", pt.size = 0, log = TRUE) + NoLegend()
slide.seq$log_nCount_Spatial <- log(slide.seq$nCount_Spatial)
plot2 <- SpatialFeaturePlot(slide.seq, features = "log_nCount_Spatial") + theme(legend.position = "right")
wrap_plots(plot1, plot2)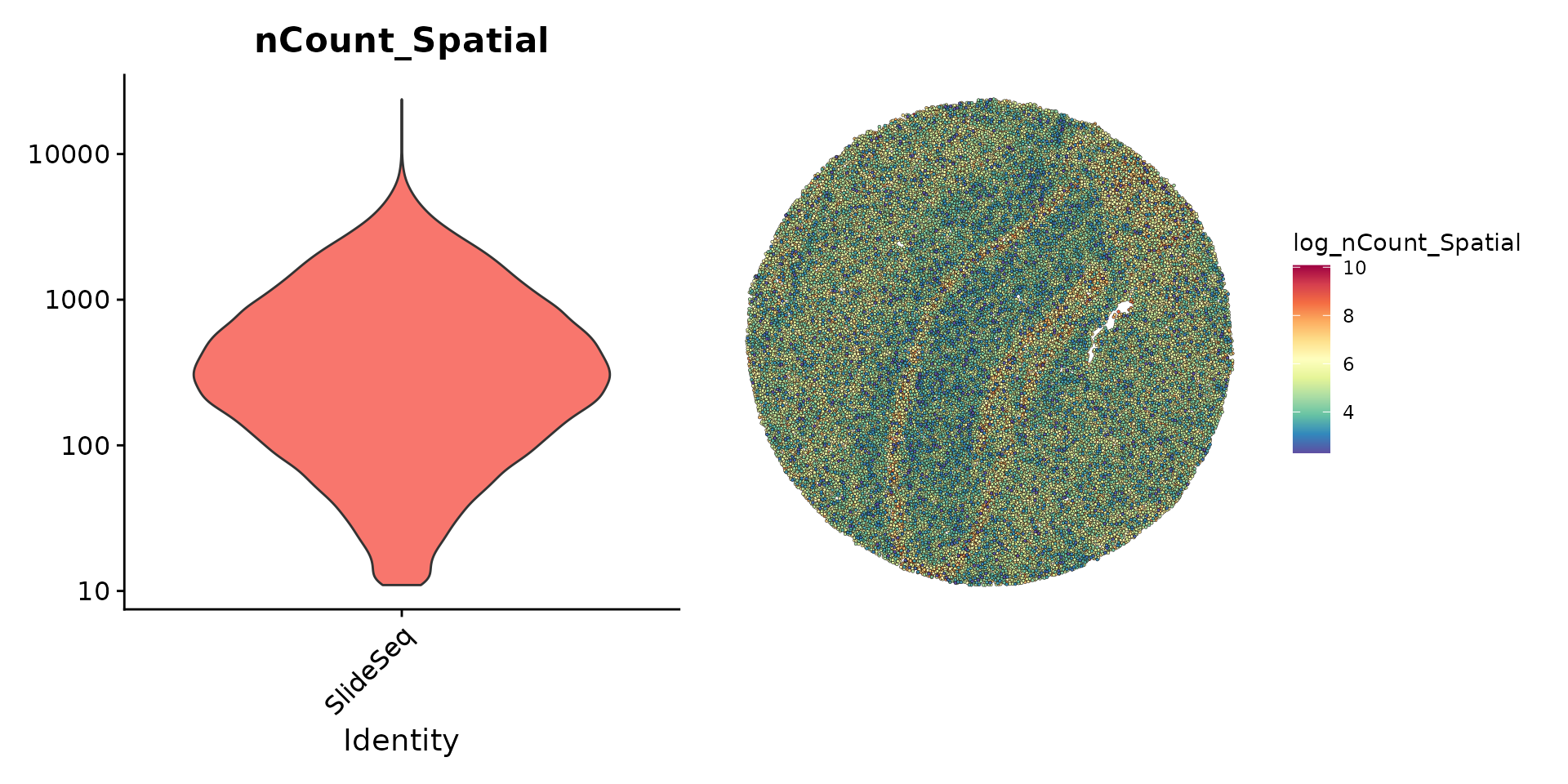
We then normalize the data using sctransform and perform a standard scRNA-seq dimensionality reduction and clustering workflow.
slide.seq <- SCTransform(slide.seq, assay = "Spatial", ncells = 3000, verbose = FALSE)
slide.seq <- RunPCA(slide.seq)
slide.seq <- RunUMAP(slide.seq, dims = 1:30)
slide.seq <- FindNeighbors(slide.seq, dims = 1:30)
slide.seq <- FindClusters(slide.seq, resolution = 0.3, verbose = FALSE)We can then visualize the results of the clustering either in UMAP space (with DimPlot()) or in the bead coordinate space with SpatialDimPlot().
plot1 <- DimPlot(slide.seq, reduction = "umap", label = TRUE)
plot2 <- SpatialDimPlot(slide.seq, stroke = 0)
plot1 + plot2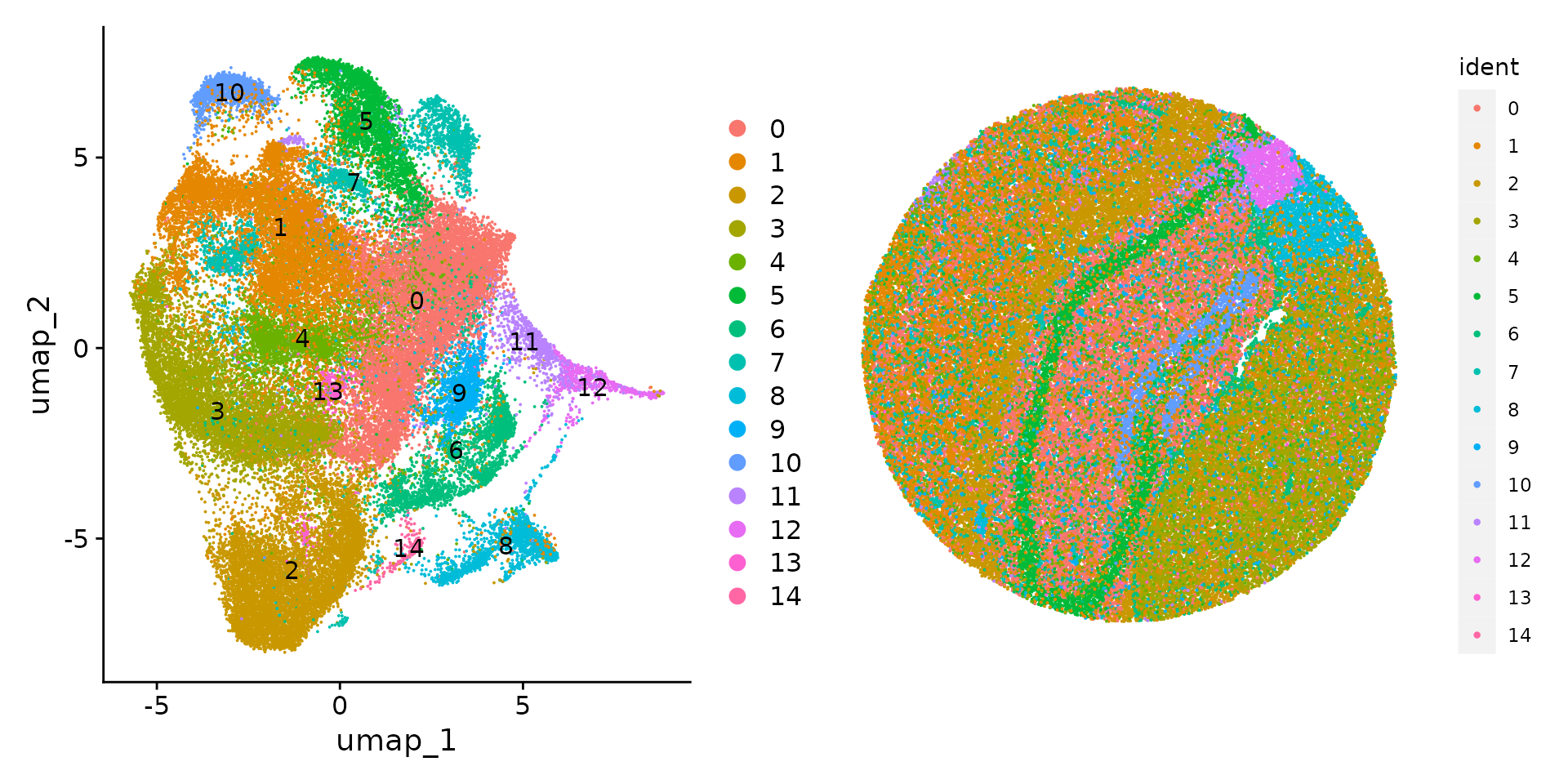
SpatialDimPlot(slide.seq, cells.highlight = CellsByIdentities(object = slide.seq, idents = c(1,
6, 13)), facet.highlight = TRUE)
Integration with a scRNA-seq reference
To facilitate cell-type annotation of the Slide-seq dataset, we are leveraging an existing mouse single-cell RNA-seq hippocampus dataset, produced in Saunders*, Macosko*, et al. 2018. The data is available for download as a processed Seurat object here, with the raw count matrices available on the DropViz website.
ref <- readRDS("../data/mouse_hippocampus_reference.rds")
ref <- UpdateSeuratObject(ref)The original annotations from the paper are provided in the cell metadata of the Seurat object. These annotations are provided at several “resolutions”, from broad classes (ref$class) to subclusters within celltypes (ref$subcluster). For the purposes of this vignette, we’ll work off of a modification of the celltype annotations (ref$celltype) which we felt struck a good balance.
We’ll start by running the Seurat label transfer method to predict the major celltype for each bead.
anchors <- FindTransferAnchors(reference = ref, query = slide.seq, normalization.method = "SCT",
npcs = 50)
predictions.assay <- TransferData(anchorset = anchors, refdata = ref$celltype, prediction.assay = TRUE,
weight.reduction = slide.seq[["pca"]], dims = 1:50)
slide.seq[["predictions"]] <- predictions.assayWe can then visualize the prediction scores for some of the major expected classes.
DefaultAssay(slide.seq) <- "predictions"
SpatialFeaturePlot(slide.seq, features = c("Dentate Principal cells", "CA3 Principal cells", "Entorhinal cortex",
"Endothelial tip", "Ependymal", "Oligodendrocyte"), alpha = c(0.1, 1))![]()
slide.seq$predicted.id <- GetTransferPredictions(slide.seq)
Idents(slide.seq) <- "predicted.id"
SpatialDimPlot(slide.seq, cells.highlight = CellsByIdentities(object = slide.seq, idents = c("CA3 Principal cells",
"Dentate Principal cells", "Endothelial tip")), facet.highlight = TRUE)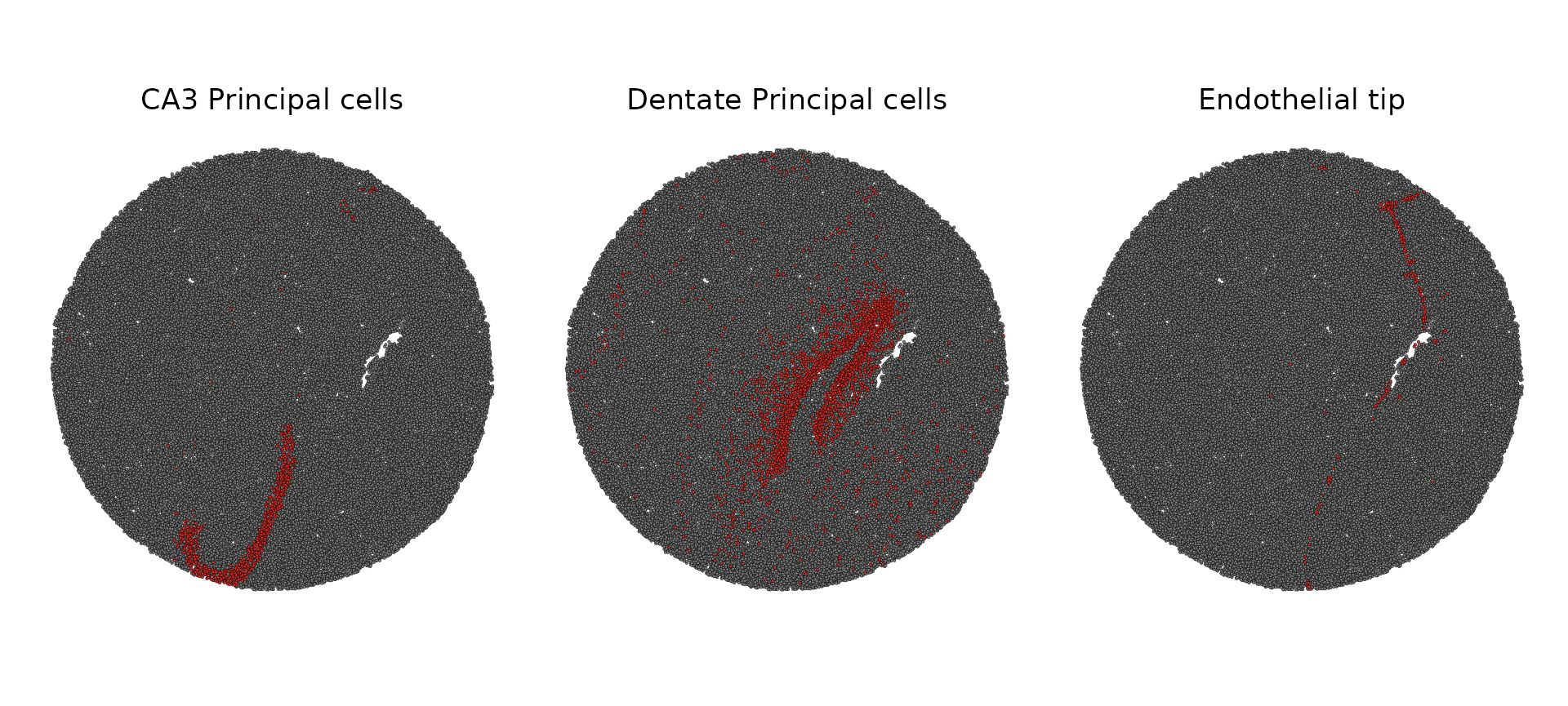
Identification of Spatially Variable Features
As mentioned in the Visium vignette, we can identify spatially variable features in two general ways: differential expression testing between pre-annotated anatomical regions or statistics that measure the dependence of a feature on spatial location.
Here, we demonstrate the latter with an implementation of Moran’s I available via FindSpatiallyVariableFeatures() by setting method = 'moransi'. Moran’s I computes an overall spatial autocorrelation and gives a statistic (similar to a correlation coefficient) that measures the dependence of a feature on spatial location. This allows us to rank features based on how spatially variable their expression is. In order to facilitate quick estimation of this statistic, we implemented a basic binning strategy that will draw a rectangular grid over Slide-seq puck and average the feature and location within each bin. The number of bins in the x and y direction are controlled by the x.cuts and y.cuts parameters respectively. Additionally, while not required, installing the optional Rfast2 package(install.packages('Rfast2')), will significantly decrease the runtime via a more efficient implementation.
DefaultAssay(slide.seq) <- "SCT"
slide.seq <- FindSpatiallyVariableFeatures(slide.seq, assay = "SCT", slot = "scale.data", features = VariableFeatures(slide.seq)[1:1000],
selection.method = "moransi", x.cuts = 100, y.cuts = 100)Now we visualize the expression of the top 6 features identified by Moran’s I.
SpatialFeaturePlot(slide.seq, features = head(SpatiallyVariableFeatures(slide.seq, selection.method = "moransi"),
6), ncol = 3, alpha = c(0.1, 1), max.cutoff = "q95")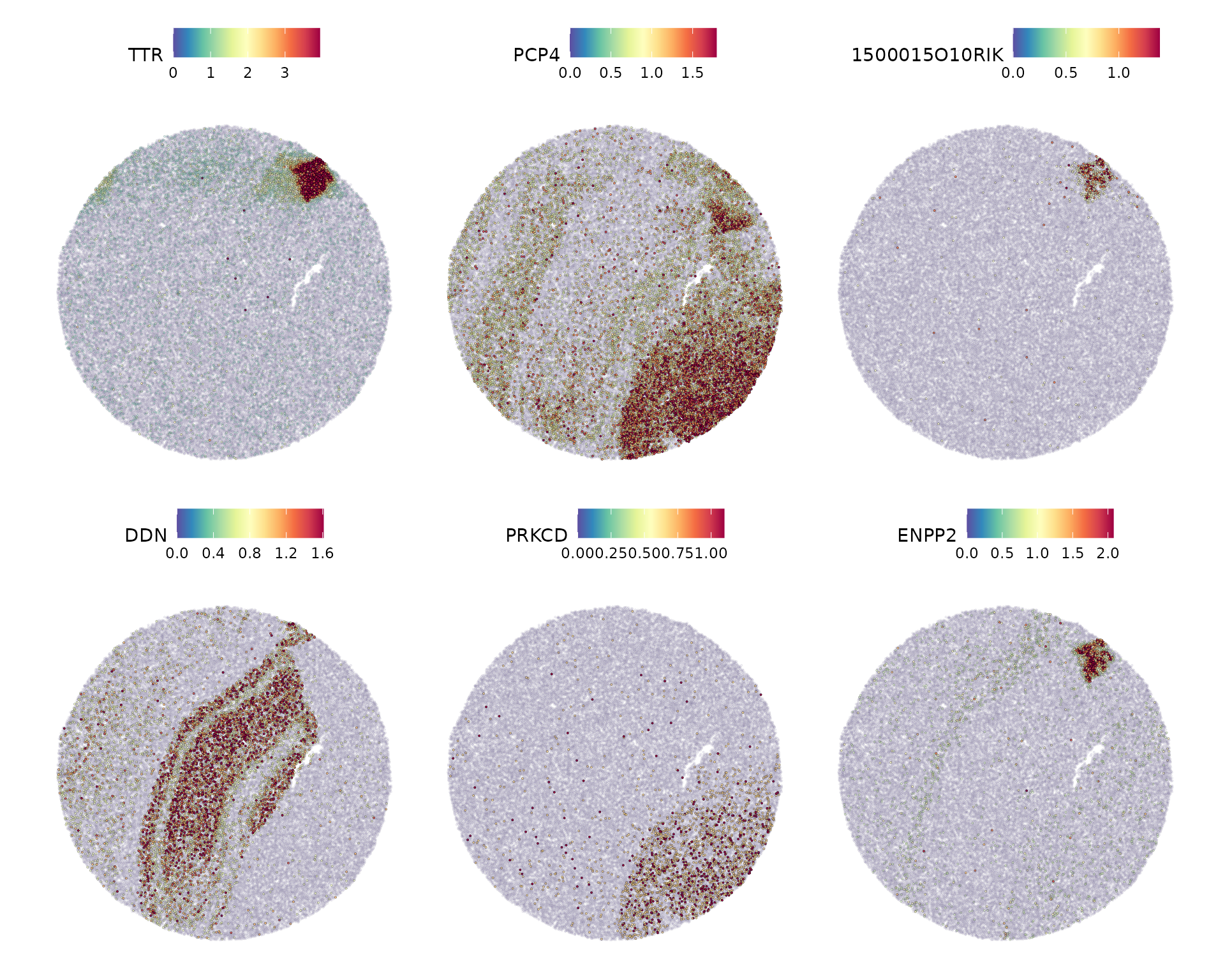
Spatial deconvolution using RCTD
While FindTransferAnchors can be used to integrate spot-level data from spatial transcriptomic datasets, Seurat v5 also includes support for the Robust Cell Type Decomposition, a computational approach to deconvolve spot-level data from spatial datasets, when provided with an scRNA-seq reference. RCTD has been shown to accurately annotate spatial data from a variety of technologies, including SLIDE-seq, Visium, and the 10x Xenium in-situ spatial platform.
To run RCTD, we first install the spacexr package from GitHub which implements RCTD.
devtools::install_github("dmcable/spacexr", build_vignettes = FALSE)Counts, cluster, and spot information is extracted from the Seurat query and reference objects to construct Reference and SpatialRNA objects used by RCTD for annotation.
library(spacexr)
# set up reference
ref <- readRDS("../data/mouse_hippocampus_reference.rds")
ref <- UpdateSeuratObject(ref)
Idents(ref) <- "celltype"
# extract information to pass to the RCTD Reference function
counts <- ref[["RNA"]]$counts
cluster <- as.factor(ref$celltype)
names(cluster) <- colnames(ref)
nUMI <- ref$nCount_RNA
names(nUMI) <- colnames(ref)
reference <- Reference(counts, cluster, nUMI)
# set up query with the RCTD function SpatialRNA
slide.seq <- SeuratData::LoadData("ssHippo")
counts <- slide.seq[["Spatial"]]$counts
coords <- GetTissueCoordinates(slide.seq)
colnames(coords) <- c("x", "y")
coords[is.na(colnames(coords))] <- NULL
query <- SpatialRNA(coords, counts, colSums(counts))Using the reference and query object, we annotate the dataset and add the cell type labels to the query Seurat object. RCTD parallelizes well, so multiple cores can be specified for faster performance.
RCTD <- create.RCTD(query, reference, max_cores = 8)
RCTD <- run.RCTD(RCTD, doublet_mode = "doublet")
slide.seq <- AddMetaData(slide.seq, metadata = RCTD@results$results_df)Next, plot the RCTD annotations. Because we ran RCTD in doublet mode, the algorithm assigns a first_type and second_type for each barcode or spot.
p1 <- SpatialDimPlot(slide.seq, group.by = "first_type")
p2 <- SpatialDimPlot(slide.seq, group.by = "second_type")
p1 | p2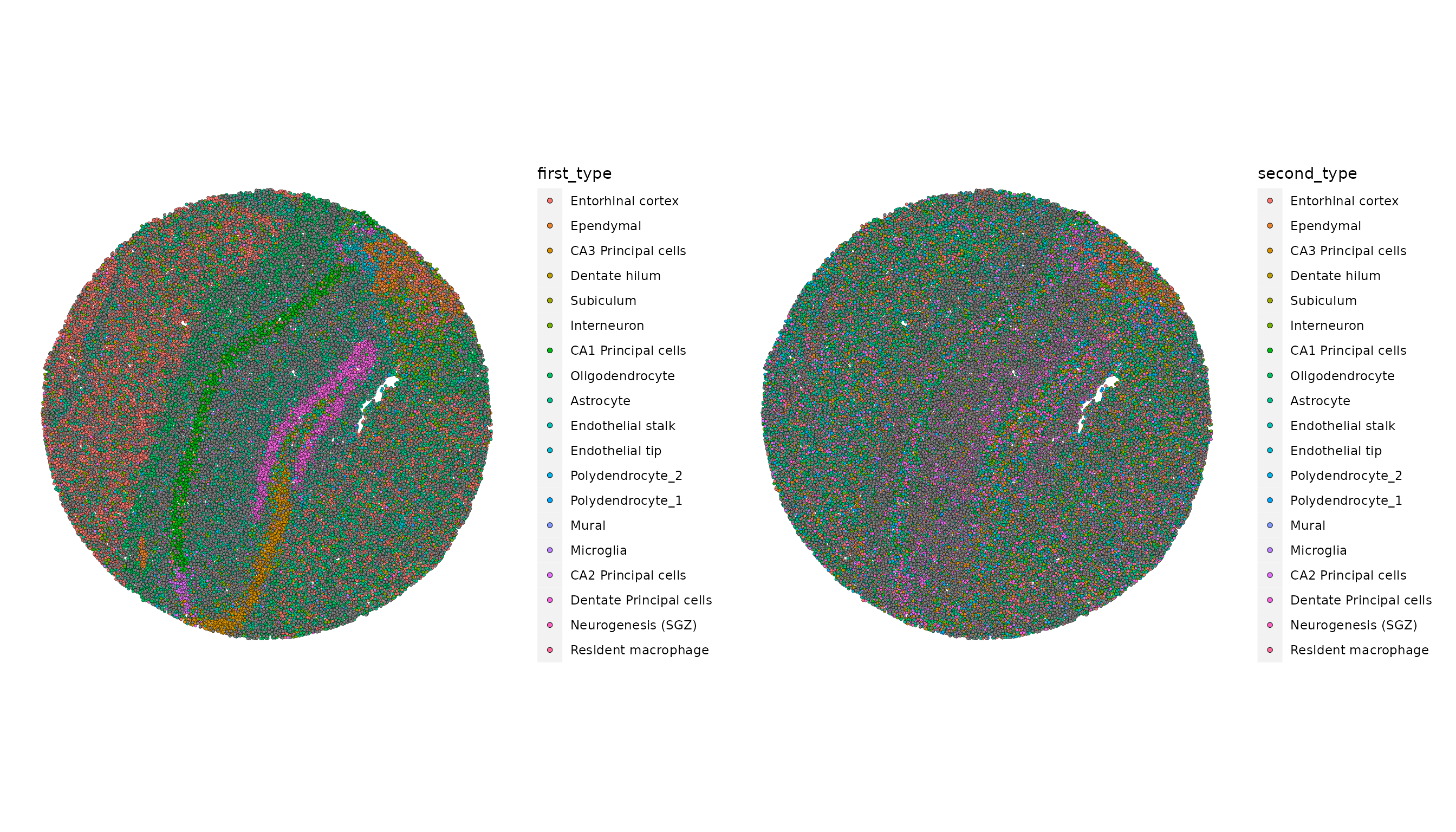
write.csv(x = t(as.data.frame(all_times)), file = "../output/timings/spatial_vignette_times.csv")Session Info
## R version 4.2.2 Patched (2022-11-10 r83330)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.6 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
## LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] spacexr_2.2.0 vembedr_0.1.5
## [3] htmltools_0.5.5 dplyr_1.1.1
## [5] patchwork_1.1.2 ggplot2_3.4.1
## [7] stxBrain.SeuratData_0.1.1 ssHippo.SeuratData_3.1.4
## [9] pbmcsca.SeuratData_3.0.0 pbmcref.SeuratData_1.0.0
## [11] pbmc3k.SeuratData_3.1.4 SeuratData_0.2.2.9001
## [13] Seurat_4.9.9.9039 SeuratObject_4.9.9.9077
## [15] sp_1.6-0
##
## loaded via a namespace (and not attached):
## [1] spam_2.9-1 systemfonts_1.0.4 plyr_1.8.8
## [4] igraph_1.4.1 lazyeval_0.2.2 splines_4.2.2
## [7] RcppHNSW_0.4.1 listenv_0.9.0 scattermore_0.8
## [10] digest_0.6.31 foreach_1.5.2 fansi_1.0.4
## [13] magrittr_2.0.3 memoise_2.0.1 doParallel_1.0.17
## [16] tensor_1.5 cluster_2.1.4 ROCR_1.0-11
## [19] limma_3.54.1 globals_0.16.2 matrixStats_0.63.0
## [22] pkgdown_2.0.7 spatstat.sparse_3.0-1 colorspace_2.1-0
## [25] rappdirs_0.3.3 ggrepel_0.9.3 textshaping_0.3.6
## [28] xfun_0.37 crayon_1.5.2 jsonlite_1.8.4
## [31] progressr_0.13.0 spatstat.data_3.0-1 iterators_1.0.14
## [34] survival_3.5-5 zoo_1.8-11 glue_1.6.2
## [37] polyclip_1.10-4 gtable_0.3.3 leiden_0.4.3
## [40] RcppZiggurat_0.1.6 future.apply_1.10.0 abind_1.4-5
## [43] scales_1.2.1 spatstat.random_3.1-4 miniUI_0.1.1.1
## [46] Rcpp_1.0.10 viridisLite_0.4.1 xtable_1.8-4
## [49] reticulate_1.28 dotCall64_1.0-2 Rfast2_0.1.4
## [52] htmlwidgets_1.6.2 httr_1.4.5 RColorBrewer_1.1-3
## [55] ellipsis_0.3.2 ica_1.0-3 farver_2.1.1
## [58] pkgconfig_2.0.3 sass_0.4.5 uwot_0.1.14
## [61] deldir_1.0-6 utf8_1.2.3 labeling_0.4.2
## [64] tidyselect_1.2.0 rlang_1.1.0 reshape2_1.4.4
## [67] later_1.3.0 munsell_0.5.0 tools_4.2.2
## [70] cachem_1.0.7 cli_3.6.1 generics_0.1.3
## [73] ggridges_0.5.4 evaluate_0.20 stringr_1.5.0
## [76] fastmap_1.1.1 yaml_2.3.7 ragg_1.2.5
## [79] goftest_1.2-3 knitr_1.42 fs_1.6.1
## [82] fitdistrplus_1.1-8 purrr_1.0.1 RANN_2.6.1
## [85] pbapply_1.7-0 future_1.32.0 nlme_3.1-162
## [88] mime_0.12 formatR_1.14 ggrastr_1.0.1
## [91] compiler_4.2.2 beeswarm_0.4.0 plotly_4.10.1
## [94] png_0.1-8 spatstat.utils_3.0-2 tibble_3.2.1
## [97] bslib_0.4.2 stringi_1.7.12 highr_0.10
## [100] desc_1.4.2 RSpectra_0.16-1 lattice_0.20-45
## [103] Matrix_1.5-3 vctrs_0.6.1 pillar_1.9.0
## [106] lifecycle_1.0.3 spatstat.geom_3.1-0 lmtest_0.9-40
## [109] jquerylib_0.1.4 RcppAnnoy_0.0.20 data.table_1.14.8
## [112] cowplot_1.1.1 irlba_2.3.5.1 httpuv_1.6.9
## [115] R6_2.5.1 promises_1.2.0.1 KernSmooth_2.23-20
## [118] gridExtra_2.3 vipor_0.4.5 parallelly_1.35.0
## [121] codetools_0.2-19 assertthat_0.2.1 fastDummies_1.6.3
## [124] MASS_7.3-58.2 rprojroot_2.0.3 withr_2.5.0
## [127] presto_1.0.0 sctransform_0.3.5.9002 parallel_4.2.2
## [130] quadprog_1.5-8 grid_4.2.2 tidyr_1.3.0
## [133] Rfast_2.0.7 rmarkdown_2.20 Rtsne_0.16
## [136] spatstat.explore_3.1-0 shiny_1.7.4 ggbeeswarm_0.7.1